배치는 대용량 데이터를 처리하기 위한 도구로 유용하게 사용되고 있습니다. 스프링 배치를 사용하며 다양한 기능에 대한 효과를 볼 수 있습니다. 배치에 성능도 필요하게되면 우리는 병렬 처리를 고민해 볼 수 있습니다. 스프링 배치는 다양한 병렬 방식을 제공해주고 있으며 이번 포스팅에서는 스프링 부트 병렬 방식에 대해서 알아보겠습니다.
Spring Batch Chunk 병렬 처리 방식
1. AsyncItemProcessor

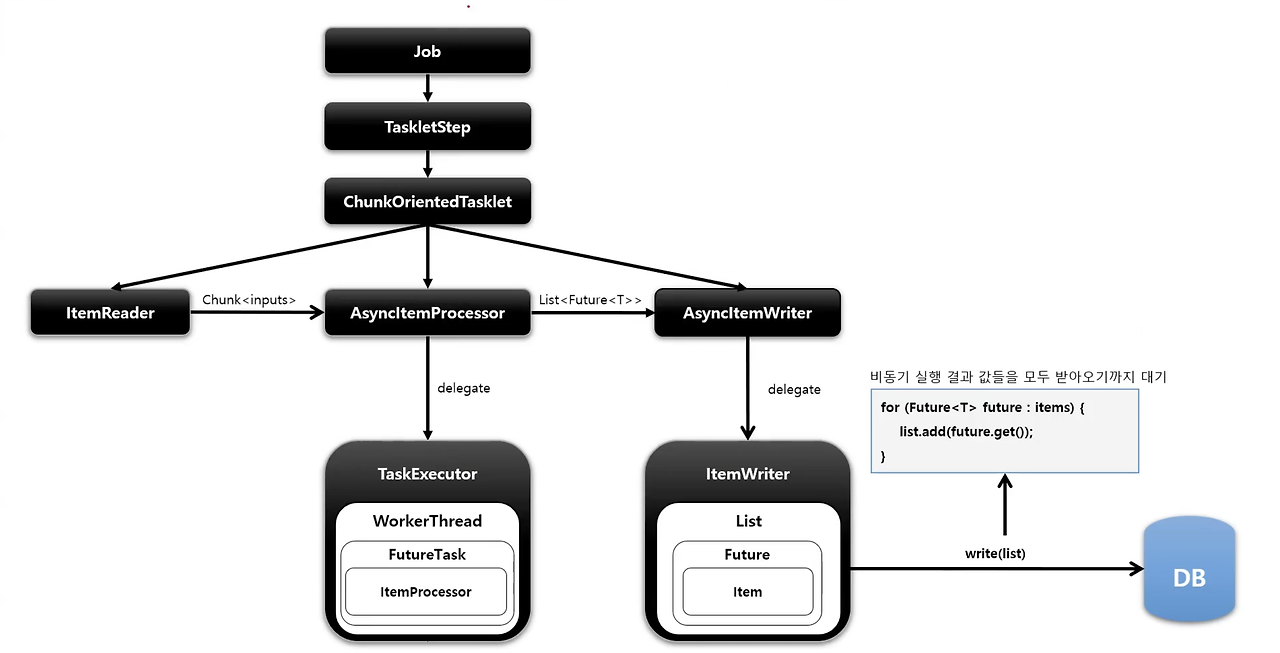
AsyncItemProcessor는 process로직을 병렬 처리하는 방식입니다. (spring-batch-integration 의존성이 별도로 필요)
process의 처리 결과로 Future를 반환하고 Writer에서 Future의 결과를 종합하여 처리합니다.
기존 Processor, Writer는 AsyncItemProcessor, AsyncItemWriter에 위임하여 코드 수정 없이 이러한 동작을 수행할 수 있습니다.
여기서 주의할 점은 AsyncItemWriter라고 writer로직이 병렬 처리되는 것은 아닌, AsyncItemWriter는 단순히 Future를 취합하여 writer에 전달될 데이터를 모은 뒤 위임된 write메서드를 호출하는 역할을 합니다.
AsyncItemProcessor 정리
Processo만 병렬로 처리된다.
- Multi-Threaded Step과 비교적으로 동시성 문제가 덜 복잡하며 reader, writer가 병목 현상이 발생되면 효과는 미비합니다.
chunk 단위의 처리 순서를 보장한다.
- chunk 단위는 순차 처리되며 내부 process가 병렬처리 된다. 순서 보장이 되기에 itemStream 적용에도 문제가 없다.
트랜잭션 관리가 어렵다.
- process에서 별도의 스레드를 파생시키므로 새로운 스레드는 chunk 트랜잭션 범위 밖으로 취급된다.
process 예외가 writer에서 처리됩니다.
- ItemWriter에서 process 처리의 Future가 unWrapping 되기에 process의 예외는 writer에서 처리됩니다. 대표적으로 skip은 process, write 어디서 발생되는지에 따라 동작방식이 달라지기에 의도치않게 동작 방식이 변경되는 부분을 인지해야합니다.
package com.example.batch.jobs;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobScope;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.integration.async.AsyncItemProcessor;
import org.springframework.batch.integration.async.AsyncItemWriter;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.support.ListItemReader;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.transaction.PlatformTransactionManager;
import java.util.Arrays;
import java.util.concurrent.Future;
@Slf4j
@Configuration
public class AsyncTestJob {
@Bean
public Job asyncJob(JobRepository jobRepository, PlatformTransactionManager batchTransactionManager) {
return new JobBuilder("asyncJob", jobRepository)
.incrementer(new RunIdIncrementer())
.start(asyncProcessorStep(jobRepository, batchTransactionManager))
.build();
}
@Bean
@JobScope
public Step asyncProcessorStep(JobRepository jobRepository, PlatformTransactionManager batchTransactionManager) {
return new StepBuilder("asyncProcessorStep", jobRepository)
.<String, Future<String>>chunk(2, batchTransactionManager)
.reader(itemReader())
.processor(asyncProcessor())
.writer(asyncItemWriter())
.build();
}
@Bean
public ThreadPoolTaskExecutor asyncTaskExecutor() { // 스레드수 설정
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(4);
executor.setCorePoolSize(8);
return executor;
}
@Bean
public ItemReader<String> itemReader() { // item reader 병렬수행하지 않음
return new ListItemReader<>(Arrays.asList("item1", "item2", "item3", "item4", "item5", "item6"));
}
@Bean
public AsyncItemProcessor<String, String> asyncProcessor() {
AsyncItemProcessor<String, String> processor = new AsyncItemProcessor<>();
processor.setTaskExecutor(asyncTaskExecutor());
processor.setDelegate((item -> { // processor 병렬 수행 위임
Thread.sleep(2000);
return item.toUpperCase();
}));
return processor;
}
@Bean
public AsyncItemWriter<String> asyncItemWriter() {
AsyncItemWriter<String> writer = new AsyncItemWriter<>();
writer.setDelegate((item) -> { // writer 병렬 수행 위임
log.info("Writing item {}", item.getItems());
});
return writer;
}
}
AsyncItemProccesor를 이용한 간단한 병렬 Job을 구현했습니다. 6개의 아이템이 chunk 2개 단위로 실행하며 2초간격으로 sleep을 주었습니다.
기본 동기방식이였으면 12초가 걸려야 하지만 병렬로 6초 이내 처리 완료한것을 로그 확인 할 수 있었습니다.

2. Multi-threaded Step
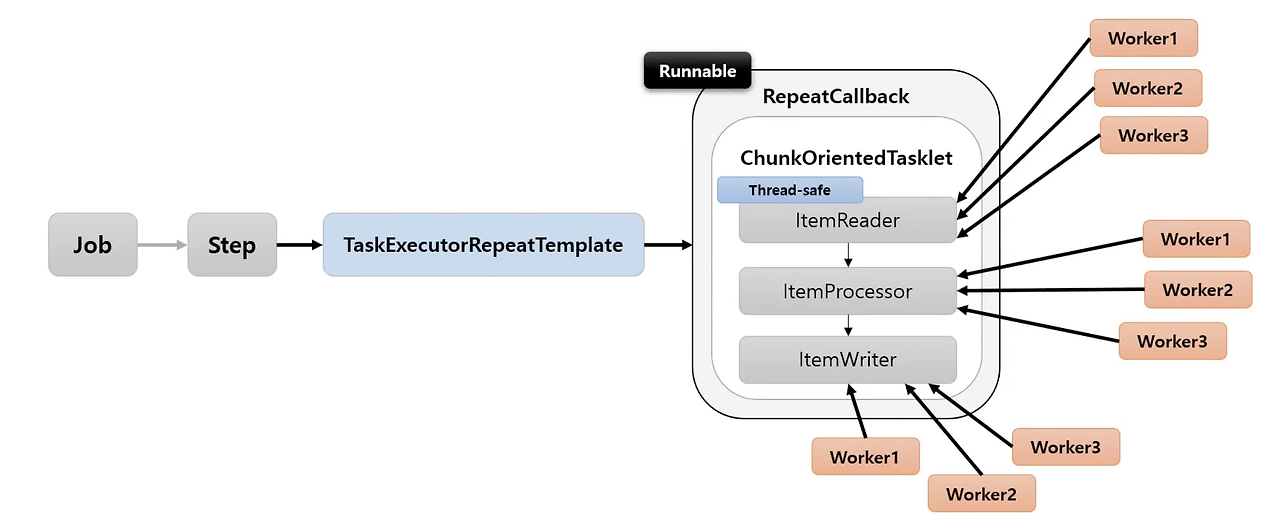
하나의 스레드에서 데이터를 읽고, 가공하고, 쓰는 과정을 처리합니다. 이러한 스레드를 여러개 만들어 chunk를 동시에 처리합니다.
Multi-threaded Step 정리
적용이 가장 간단합니다.
Spring Batch에서 지원하는 병렬 처리 기능은 배치 로직을 수정하지 않고도 간단히 적용할 수 있는 게 장점입니다. Multi-threaded Step는 특히 적용이 간단합니다.
Multi-threaded Step은 트랜잭션 처리가 용이합니다.
read, process, write과정이 하나의 스레드에서 처리됩니다. 스레드 내부에서 트랜잭션이 열리고 데이터를 읽고, 가공하고, 쓰는 작업을 통해 트랜잭션 처리가 용이합니다.
Multi-threaded Step은 read, process, write 모든 부분에서 병렬 처리가 적용됩니다.
Chunk처리 단위 자체를 병렬 처리하기 때문에 Reader, Processor, Writer 모든 부분이 병렬 처리됩니다. 따라서 어떤 부분에 병목이 발생하던지 처리 속도 개선에 효과적입니다.
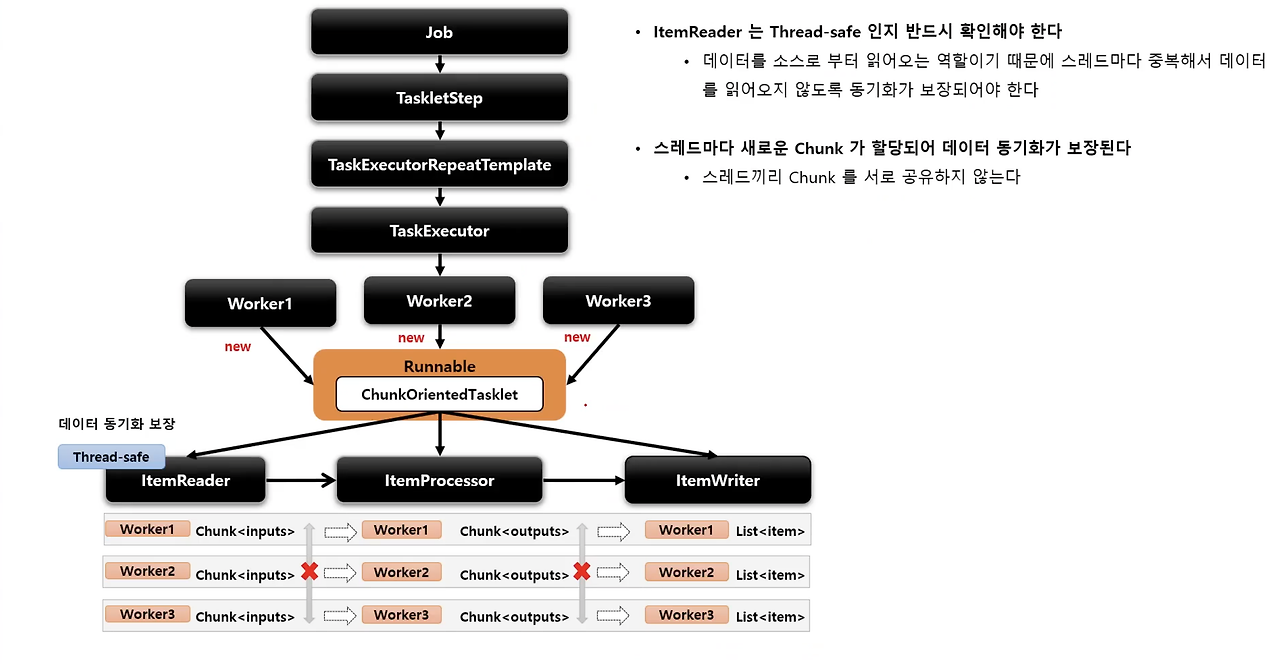
Multi-threaded Step은 Chunk 단위 처리 순서를 보장할 수 없습니다.
어떤 스레드의 chunk처리가 먼저 끝나는지 보장할 수 없습니다. chunk 처리 순서를 보장할 수 없다면 비즈니스 로직상 순서 처리가 중요한 배치에는 적용할 수 없습니다.
Multi-threaded Step은 DB connection pool size에 대한 고려가 필요합니다.
Multi-threaded Step은 스레드마다 chunk가 할당되어 처리되기 때문에 스레드 수와 비례하여 트랜잭션이 발생합니다.
package com.example.batch.jobs;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobScope;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.support.ListItemReader;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.transaction.PlatformTransactionManager;
import java.util.Arrays;
@Slf4j
@Configuration
public class MultiThreadStepTestJob {
@Bean
public Job multiThreadStepJob(JobRepository jobRepository, PlatformTransactionManager batchTransactionManager) {
return new JobBuilder("multiThreadStepJob", jobRepository)
.incrementer(new RunIdIncrementer())
.start(multiThreadStepStep(jobRepository, batchTransactionManager))
.build();
}
@Bean
@JobScope
public Step multiThreadStepStep(JobRepository jobRepository, PlatformTransactionManager batchTransactionManager) {
return new StepBuilder("multiThreadStepStep", jobRepository)
.<String, String>chunk(2, batchTransactionManager)
.reader(itemReader())
.processor(itemProcessor())
.writer(itemWriter())
.taskExecutor(asyncTaskExecutor2())
.build();
}
@Bean
public ThreadPoolTaskExecutor asyncTaskExecutor2() { // 스레드수 설정
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(4); // 기본 스레드 풀 크기
executor.setMaxPoolSize(8); // 4개의 스레드가 이미 처리중인데 작업이 더 있을 경우 몇개까지 스레드를 늘릴 것인지
executor.setThreadNamePrefix("async-thread"); // 스레드 이름 prefix
return executor;
}
public ItemReader<String> itemReader() {
return new ListItemReader<>(Arrays.asList("a", "b", "c"));
}
public ItemProcessor<String, String> itemProcessor() {
return item -> {
Thread.sleep(2000);
return item.toUpperCase();
};
}
public ItemWriter<String> itemWriter() {
return item -> {
log.info("Writing item {}", item.getItems());
};
}
}Multi-threaded Step를 이용한 간단한 병렬 Job을 구현했습니다. 3개의 아이템이 chunk 2개 단위로 실행하며 2초간격으로 sleep을 주었습니다.
기본 동기방식이였으면 6초가 걸려야 하지만 병렬로 4초 이내 처리 완료한것을 로그 확인 할 수 있었습니다.

3. Parallel Steps
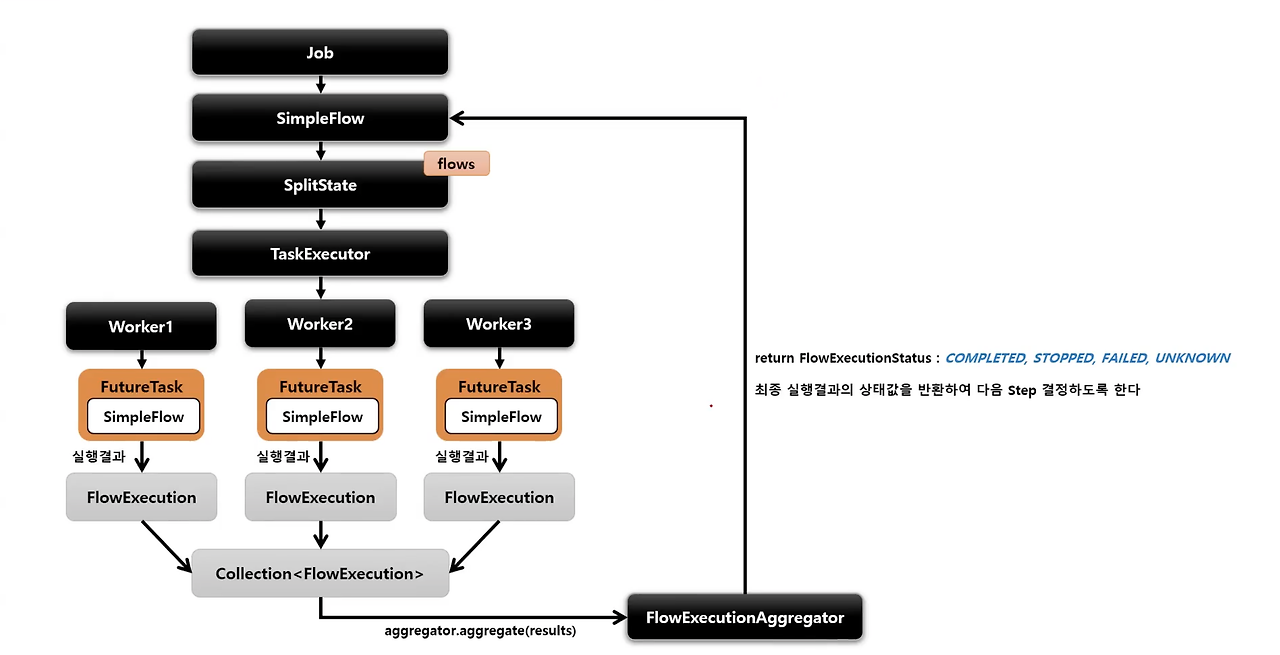
SplitState를 활용하여 여러개의 Flow 들을 병렬적으로 수행하는 구조입니다. 실행이 완료 된 이후 FlowExecutionStatus 결과들을 취합해서 다음 단계 결정을 진행합니다.
Parallel Steps 정리
SplitState를 사용하여 여러 Flow 병렬 실행
Job이 Flow를 통해 SplitState를 만들어서 TaskExecutor를 통해 스레드를 생성하고 각각의 FutureTask를 통해 멀티테스킹을 유도합니다.
Thread-Safe
멀티스레드 환경에서의 배치잡들 처럼 각각의 스레드간 데이터 공유가 일어나지 않아 Thread-safe 합니다.
병렬 처리 후 흐름 제어
모든 Flow의 실행이 완료되면, 취합된 결과를 바탕으로 다음 스텝으로 이동하거나 재처리 등의 결정을 내립니다.
package com.example.batch.jobs;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.job.builder.FlowBuilder;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.job.flow.Flow;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.transaction.PlatformTransactionManager;
@Slf4j
@Configuration
public class ParallelStepTestJob {
@Bean
public Job parallelStepJob(JobRepository jobRepository, PlatformTransactionManager batchTransactionManager) {
return new JobBuilder("parallelStepJob", jobRepository)
.incrementer(new RunIdIncrementer())
.start(flow1(jobRepository, batchTransactionManager))
.split(taskExecutor())
.add(flow1(jobRepository, batchTransactionManager), flow2(jobRepository, batchTransactionManager))
.next(flow3(jobRepository, batchTransactionManager))
.end().build();
}
@Bean
public ThreadPoolTaskExecutor taskExecutor() { // 스레드수 설정
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(4);
executor.setCorePoolSize(8);
return executor;
}
public Flow flow1(JobRepository jobRepository, PlatformTransactionManager batchTransactionManager) {
return new FlowBuilder<Flow>("flow1")
.start(step1(jobRepository, batchTransactionManager))
.build();
}
public Flow flow2(JobRepository jobRepository, PlatformTransactionManager batchTransactionManager) {
return new FlowBuilder<Flow>("flow2")
.start(step2(jobRepository, batchTransactionManager))
.next(step3(jobRepository, batchTransactionManager))
.build();
}
public Flow flow3(JobRepository jobRepository, PlatformTransactionManager batchTransactionManager) {
return new FlowBuilder<Flow>("flow3")
.start(step4(jobRepository, batchTransactionManager))
.build();
}
public Step step1(JobRepository jobRepository, PlatformTransactionManager batchTransactionManager) {
return new StepBuilder("step1", jobRepository)
.tasklet(((contribution, chunkContext) -> {
Thread.sleep(3000);
log.info("step1 myTaskletStep started =============");
return RepeatStatus.FINISHED;
}), batchTransactionManager).build();
}
public Step step2(JobRepository jobRepository, PlatformTransactionManager batchTransactionManager) {
return new StepBuilder("step2", jobRepository)
.tasklet(((contribution, chunkContext) -> {
Thread.sleep(1000);
log.info("step2 myTaskletStep started =============");
return RepeatStatus.FINISHED;
}), batchTransactionManager).build();
}
public Step step3(JobRepository jobRepository, PlatformTransactionManager batchTransactionManager) {
return new StepBuilder("step3", jobRepository)
.tasklet(((contribution, chunkContext) -> {
Thread.sleep(6000);
log.info("step3 myTaskletStep started =============");
return RepeatStatus.FINISHED;
}), batchTransactionManager).build();
}
public Step step4(JobRepository jobRepository, PlatformTransactionManager batchTransactionManager) {
return new StepBuilder("step4", jobRepository)
.tasklet(((contribution, chunkContext) -> {
Thread.sleep(1000);
log.info("step4 myTaskletStep started =============");
return RepeatStatus.FINISHED;
}), batchTransactionManager).build();
}
}
순차적으로 Flow를 3개를 만들어주었으면 처음에는 1번, 2번이 병렬 수행후 3번이 수행될 수 있게 하였습니다.
2번 Flow 내에서는 스텝 2 / 3번이 순차로 실행될것입니다.
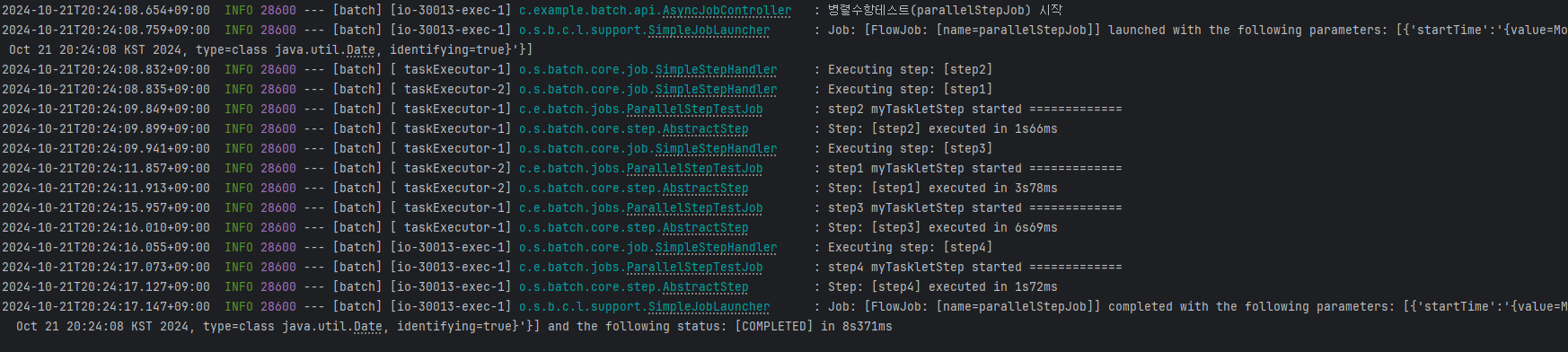
4. Partitioning

partitioning은 step을 특정 조건으로 파티셔닝하고 파티셔닝 된 step을 병렬 처리하는 방식입니다.
partitioning은 Thread에 step을 할당하여 처리하는 방식이며 step은 StepExecution, StepExecutionContext를 갖기 때문에 worker step마다 개별적인 실행 상태를 관리할 수 있습니다.
PartitionStep
파티셔닝 기능을 수행하는 Step 구현체로 파티셔닝을 수행 후 StepExecutionAggregator를 사용해서 StepExecution의 정보를 최종 집계한다.
PartitionHandler
PartitionStep에 의해 호출되며 스레드를 생성해서 WorkStep을 병렬로 실행합니다.
WorkStep에서 사용할 StepExecution 생성은 StepExecutionSplitter와 Partitioner에게 위임한 후 최종 결과를 담은 StepExecution을 PartitionStep에 반환한다
StepExecutionSplitter
WorkStep에서 사용할 StepExecution을 gridSize(= 스레드수) 만큼 생성한 후 Partitioner를 통해 ExecutionContext를 얻어서 StepExecution에 매핑한다
Partitioner
StepExecution에 매핑 할 ExecutionContext를 gridSize 만큼 생성한다
Partitioning 정리
트랜잭션 관리에 용이합니다.
chunk 내부 로직은 동일한 스레드로 처리되며 처리 과정 중 새로운 스레드가 파생되지 않으므로 트랜잭션 관리가 용이합니다.
일부 Worker Step 실패 시 다른 Worker Step에 영향을 주지 않습니다.
다른 병렬 처리 방식은 예외 시 어플리케이션이 종료가 되나, partitioning은 일부 worker step에서 예외가 발생하여 종료가 되더라도 다른 worker step에 영향을 주지 않습니다.
모든 worker step들이 종료되고 그 결과를 manager step에서는 집계하여 배치의 최종 서공, 실패를 기록합니다.
※ Skip을 사용시 최종적으로 배치는 성공처리가 될 수 있으며 실패에 대한 기록이 없어 배치를 재처리에 어려움을 겪을수 있습니다.
구현이 복잡합니다.
다른 병렬 처리 방식에 비해 구현해야하는 코드가 많고 복잡하기에 자주 사용되지 않는 방식입니다.
Partitioning은 Chunk 단위 처리 순서를 보장 할 수 없습니다.
스레드마다 chunk를 처리하므로 데이터 처리 순서를 보장 할 수 없습니다.
package com.example.batch.jobs;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.core.partition.support.Partitioner;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.item.ExecutionContext;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.support.ListItemReader;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.transaction.PlatformTransactionManager;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
@Slf4j
@Configuration
public class PartitioningTestJob {
@Bean
public Job partitioningJob(JobRepository jobRepository, PlatformTransactionManager batchTransactionManager) {
return new JobBuilder("partitioningJob", jobRepository)
.incrementer(new RunIdIncrementer())
.start(partitioningStep(jobRepository, batchTransactionManager))
.build();
}
@Bean
public ThreadPoolTaskExecutor partitioningTaskExecutor() { // 스레드수 설정
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(4);
executor.setCorePoolSize(8);
return executor;
}
@Bean
public Step partitioningStep(JobRepository jobRepository, PlatformTransactionManager batchTransactionManager) {
return new StepBuilder("partitioningStep", jobRepository)
.partitioner(partitioningSubStep(jobRepository, batchTransactionManager).getName(), new ColumnRangePartitioner()) // 1
.step(partitioningSubStep(jobRepository, batchTransactionManager)) // 스텝
.gridSize(12) // 파티션 개수
.taskExecutor(partitioningTaskExecutor()) // 스레드 생성
.build();
}
@Bean
public Step partitioningSubStep(JobRepository jobRepository, PlatformTransactionManager batchTransactionManager) {
return new StepBuilder("partitioningSubStep", jobRepository)
.<String, String>chunk(3, batchTransactionManager)
.reader(itemReader())
.writer(itemWriter())
.build();
}
public ItemReader<String> itemReader() {
return new ListItemReader<>(Arrays.asList("a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z", "0", "1", "2", "3", "4", "5", "6", "7", "8", "9"));
}
public ItemWriter<String> itemWriter() {
return item -> {
log.info("Writing item {}", item.getItems());
};
}
public static class ColumnRangePartitioner implements Partitioner {
private final int min = 0;
private final int max = 36; // 최대값 (예: 데이터의 총 크기)
@Override
public Map<String, ExecutionContext> partition(int gridSize) {
log.info("Partitioning grid size {}", gridSize);
Map<String, ExecutionContext> result = new HashMap<>();
// 각 파티션의 범위 계산 (총 범위를 gridSize로 나눈다)
int targetSize = (max - min) / gridSize;
int start = min;
int end = start + targetSize - 1;
// 파티션별로 ExecutionContext 생성
for (int i = 0; i < gridSize; i++) {
ExecutionContext context = new ExecutionContext();
// 파티션에 대한 정보를 ExecutionContext에 저장
context.putInt("minValue", start);
context.putInt("maxValue", end);
// 파티션 이름 지정 (partition0, partition1, ...)
result.put("partition" + i, context);
// 다음 파티션의 범위 계산
start = end + 1;
end = i == gridSize - 2 ? max : start + targetSize - 1; // 마지막 파티션 범위 조정
}
log.info("{}", result);
return result;
}
}
}
36개의 아이템을 만들어주었으며, 파티션을 12개로 잡아주었습니다. 파티션별로 3개의 아이템이 수행될 것으로 보이며 개별적인 수행은 아래와 같이 수행되었습니다.

Partitioning 좀더 알아보기
1. PartitionStepBuilder에 build를 보면 PartitionStep의 Step이 생성되는것을 볼수있습니다.

2. PartitionStep을 보면 doExcute에 등록된 핸들러로 위임되는것을 확인할 수있다. (build를 보면 기본 TaskExecutorPartitionHandler가 등록되는것을 볼수있다.)
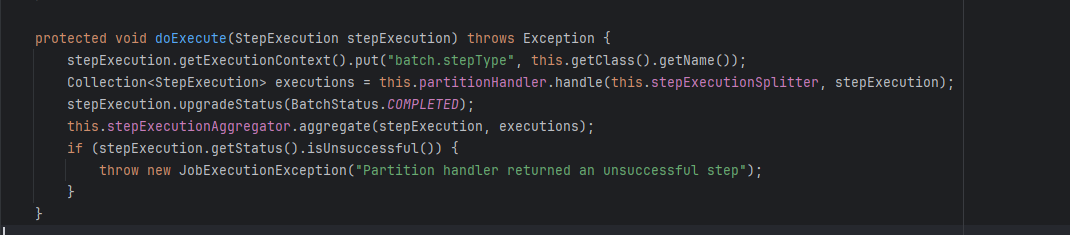
3. TaskExecutorPartitionHandler는 AbstractPartitionHandler 추상 클래스의 구현체로 먼저 추상클래스에 handle가 수행되어 StepExecutionSplitter 수행됩니다. (build시에 기본으로 SimpleStepExecutionSplitter를 등록해둔다)
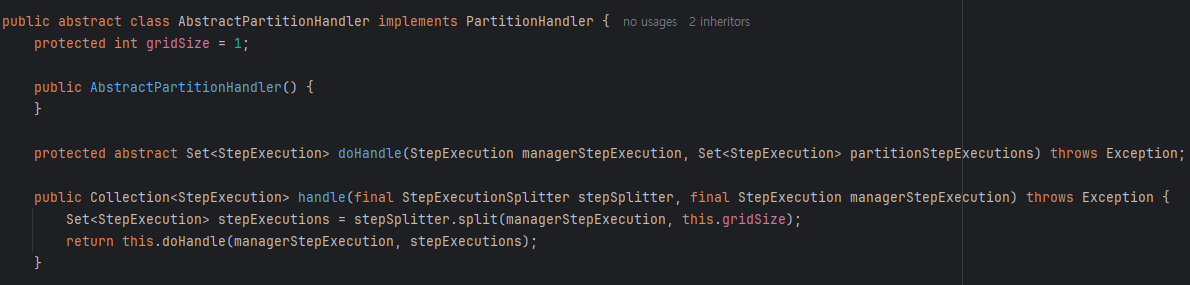
4. StepExecutionSplitter의 split를 보면 설정한 gridSize로 Step들을 생성하고있습니다. getContexts를 보게되면 클라이언트가 등록한 partitioner의 partition으로 분리되는것을 볼 수있다.

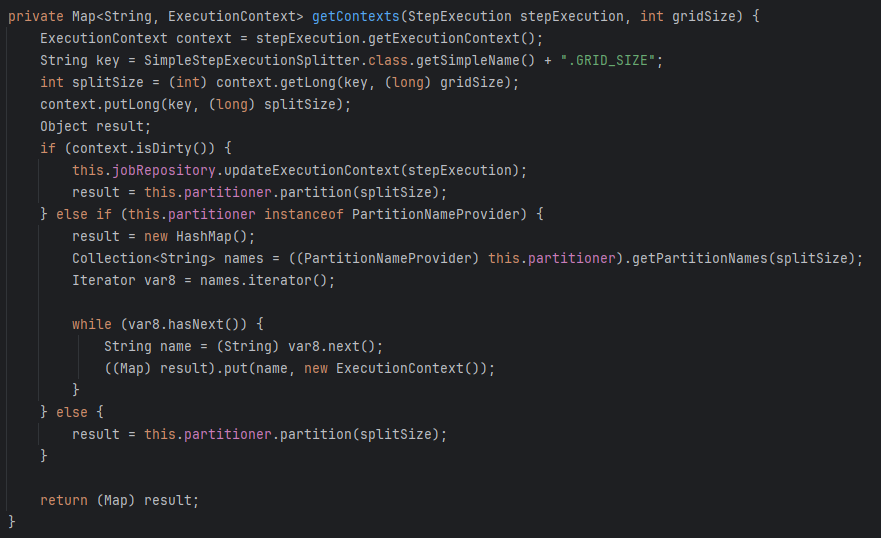
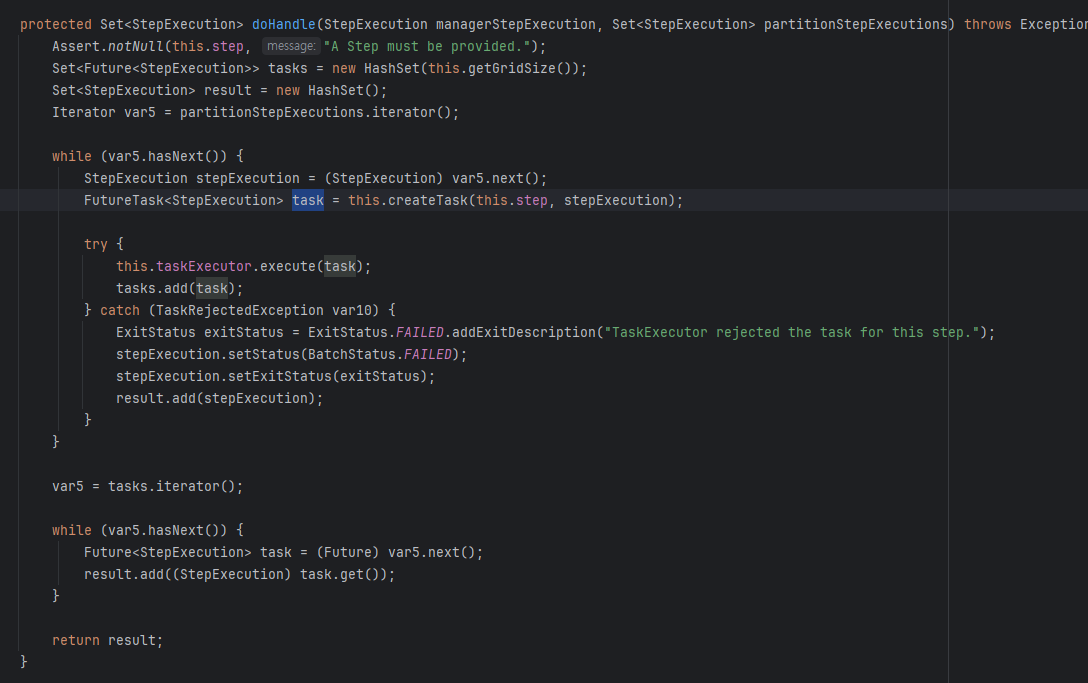
5. 위에서 생성된 partitionStepExecutions는 구현체(TaskExecutorPartitionHandler)의 doHandle로 실행이된다. 개별 task가 생성되어 execute가 되며 개별적인 스텝으로 처리되는것이 아닌 등록된 스텝에 의해서 실행되는 것을 볼 수 있다.

스프링 배치에 다양한 병렬 수행 방법을 익혀볼 수 있었다. 개발자는 자신에 환경에 가장 알맞는 병렬 방식을 선택하여 적절하게 처리하는게 중요해보입니다.
'Spring' 카테고리의 다른 글
| 헥사고날 아키텍처(Hexagonal Archtecture) (0) | 2024.10.30 |
|---|---|
| Spring Scope와 ObjectProvider, proxyMode (0) | 2024.10.20 |
| Spring Boot Batch 적용하기 - 2 (0) | 2024.09.21 |
| Spring Boot Batch 적용하기 - 1 (1) | 2024.09.18 |
| Spring Boot + Quartz 적용하기 - 3 (1) | 2024.09.17 |



